

-

Dataiku
-
Kaggle
2023-06-16

本記事では、kaggleのFood Demand Forecasting(食材需要予測)を分析ツールDataikuを利用して分析してみたいと思います。
今回使用するデータは、kaggle「Food Demand Forecasting」です。
目次
-
1.
Kaggleとは
-
2.
Dataikuとは
-
3.
kaggle「食材需要予測」
-
4.
データの読み込み
-
5.
データの加工
-
6.
予測モデルの構築
-
7.
おわりに
Kaggleとは
Kaggleとは、データサイエンティスト達が、自分たちのデータ分析力を磨く場として機能しているプラットフォームとなります。kaggleとはカグルと読み、kaggleに参加し、スキルを磨く方々をカグラーと呼びます。
the home of Data Science & Machine Learning
と表記されるように、データサイエンスと機械学習の家と呼ばれ、世界中の、機械学習・データサイエンスに携わる約40万人が集まるコミュニティです。
Kaggleの中では、企業や政府などの組織と、データ分析のプロであるデータサイエンティストや機械学習エンジニアを繋げるプラットフォームとして機能しており単純にエンジニアと企業をマッチングするのではなく、コンペも行われ盛り上がりをみせています。
Dataikuとは
Dataikuは、データサイエンスと機械学習のためのエンドツーエンドプラットフォームです。
データの準備からモデルの展開までをサポートし、効率的なチームコラボレーションが実現できます。
ビジネスユーザーやデータサイエンティストは、異種のデータソースからのデータ統合やモデル構築を簡素化できます。
豊富なデータ可視化機能やセキュリティ対策も特長です。
kaggle「食材需要予測」
複数の都市で運営されている食事配達会社のデータです。
顧客から注文された食事を出荷するために、各都市に配達センターがあります。
クライアントは、センターが将来の数週間の需要予測を行い、原材料の在庫を適切に計画するように求めています。
データの読み込み
まずは、データをDataikuで読み込みます。

| fulfilment_center_info | センター情報 |
| meal_info | 食事情報 |
| train | 需要履歴データ |
| test | 予測対象 |
データの加工
読み込んだデータを機械学習を実行するために一つのデータを作成します。
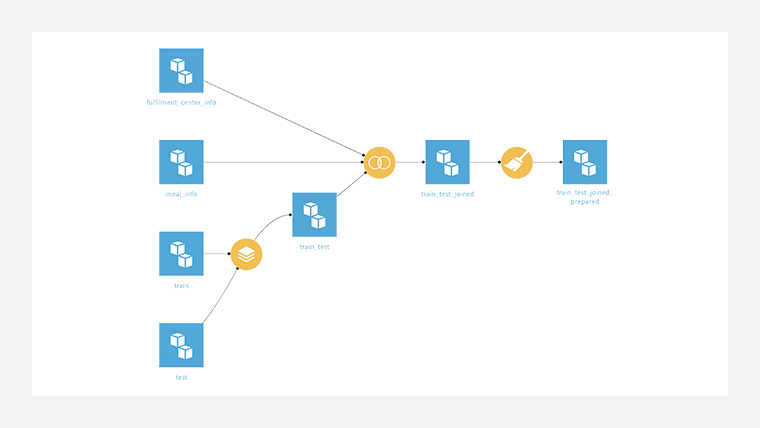
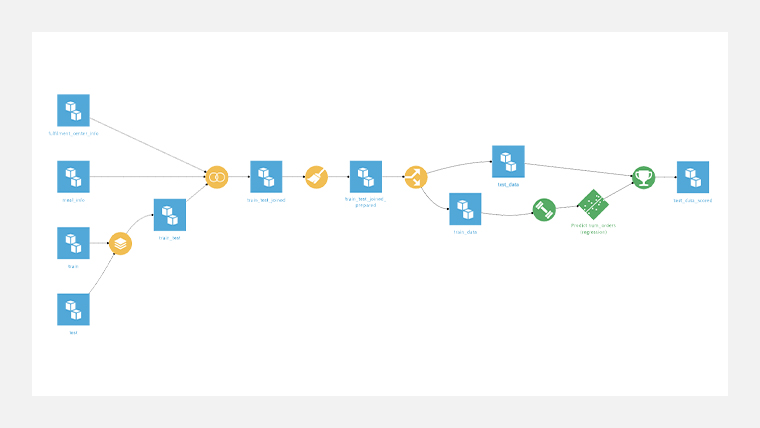
StackレシピとJoinレシピ、Prepareレシピを使って、下図のようにフローを作成しました。
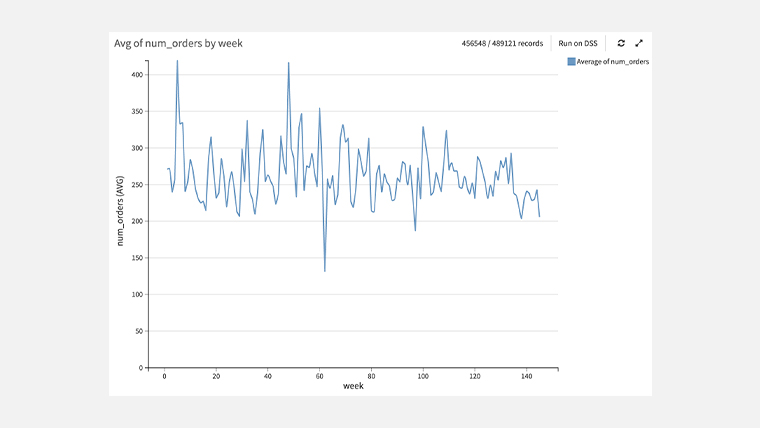
週別の平均注文数の推移
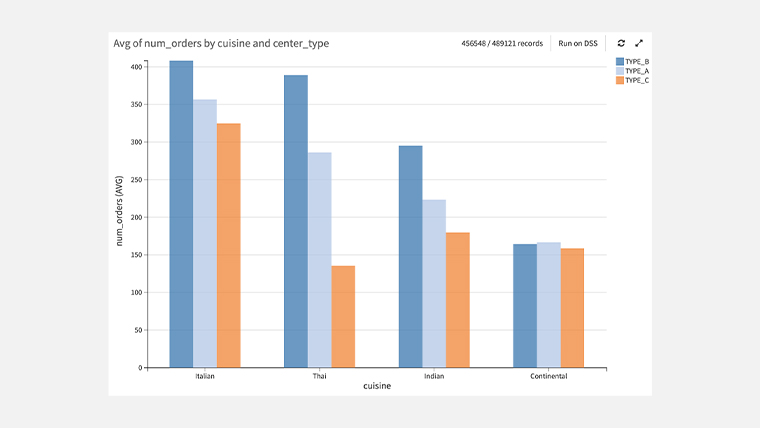
料理別センタータイプ別の平均注文数
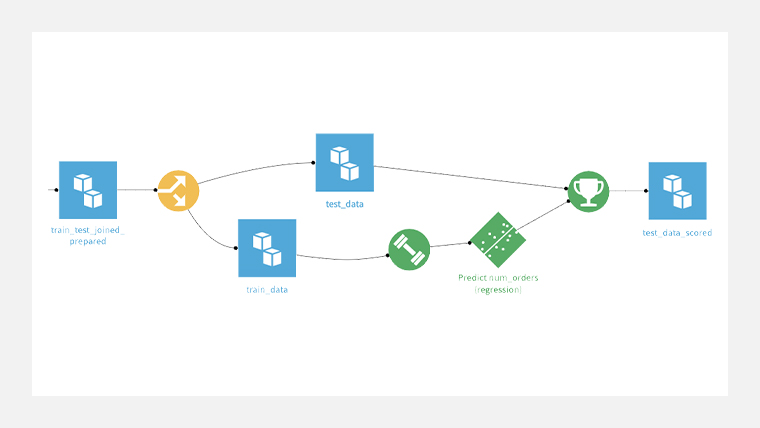
予測モデルの構築
学習用のデータとテスト用のデータに分けて学習用のデータで予測モデルを構築します。
下図のダンベルのアイコン部分が学習で、ひし形のアイコンが出来上がったモデルです。
デフォルトだとランダムフォレストとRidge回帰の2つですが、他にもたくさんアルゴリズムが提供されてるので、とりあえずいっぱい実行してみます。
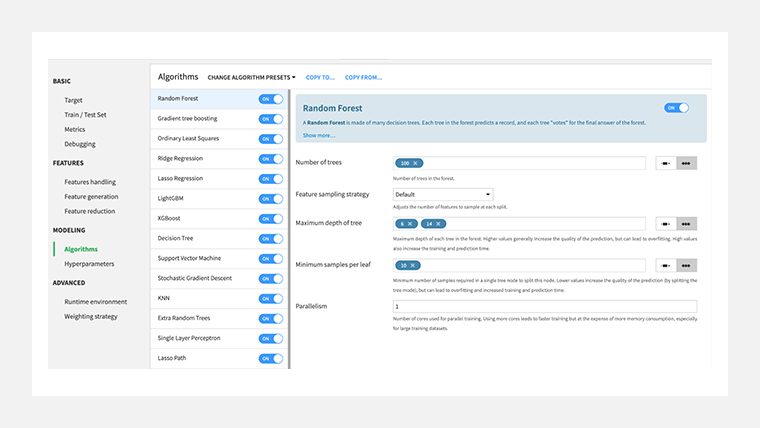
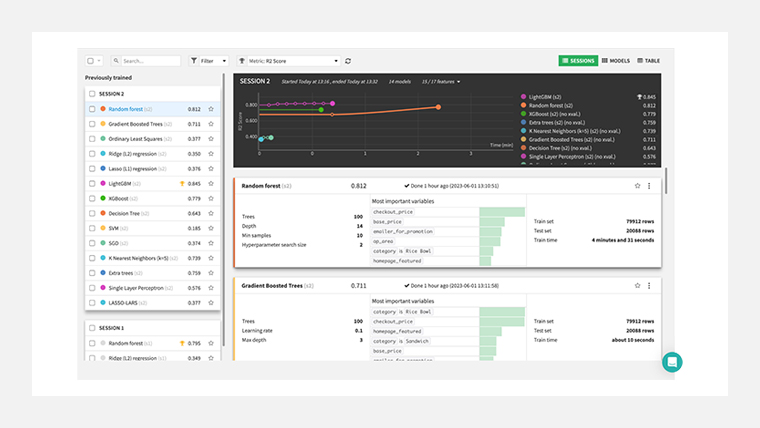
結果、下図のようになりました。
このデータでは、LightGBMが一番精度が高いようです。
最後に、テストデータで予測をします。
Scoreレシピで実行すると↓のようにprediction予測結果のカラムが追加されます。
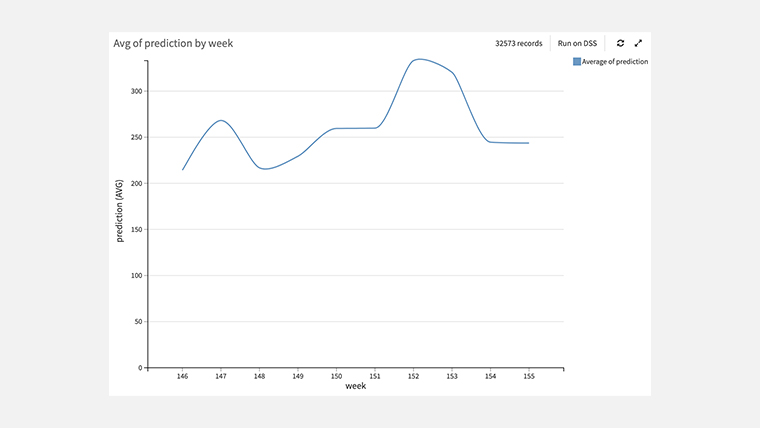
週別の平均注文数(予測)の推移
任意のセンターIDの週別食事別注文数の予測結果
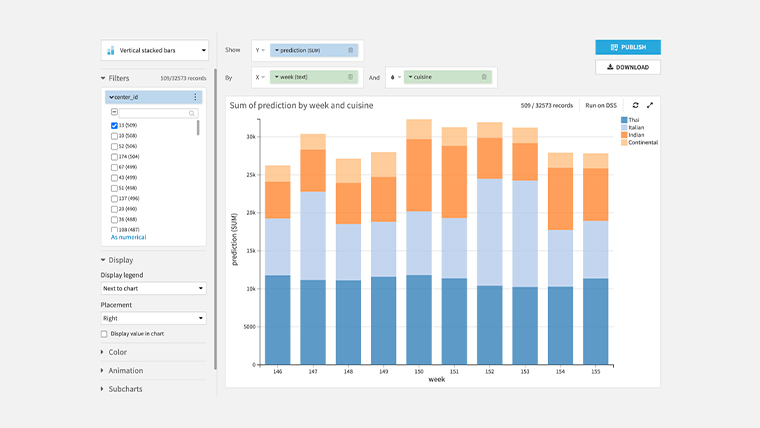
おわりに
kaggle食事予測データを使って、データの読み込みからモデルの構築、予測まで実行してみました。
いかがでしたでしょうか。Dataikuを使うと、簡単に出来ますね!
最後に、今回作成したフローを載せておきます。
関連記事





本社 〒891-3604 鹿児島県熊毛郡中種子町野間5185-1
TEL : 0997-28-3393
支社 〒150-0022 東京都渋谷区恵比寿南1-20-6第21荒井ビル4F
TEL : 03-6890-2598