

-

ChatGPT
-
Dataiku
2023-07-13

目次
-
1.
はじめに
-
2.
給与分析:データ分析編
-
3.
データの可視化
-
4.
APPENDIX
はじめに
こんにちは、株式会社VillageAI取締役の松本祐輝です。
『DataikuとChatGPTで給与分析 どんなデータスキルが稼げるのか?【データ加工編】』の続きです。
DataikuのOpenAI GPTとChatGPTを使って、どんなデータスキルが稼げるのか?を
分析して明らかにしてみたいと思います。
給与分析:データ分析編
データの可視化
データの可視化
データを加工しやすい形に変形(Unpivot)させてChatsタブで可視化していきます。
変形の前にあとで元に戻せるようにWindowレシピで行番号のカラムを追加しています。
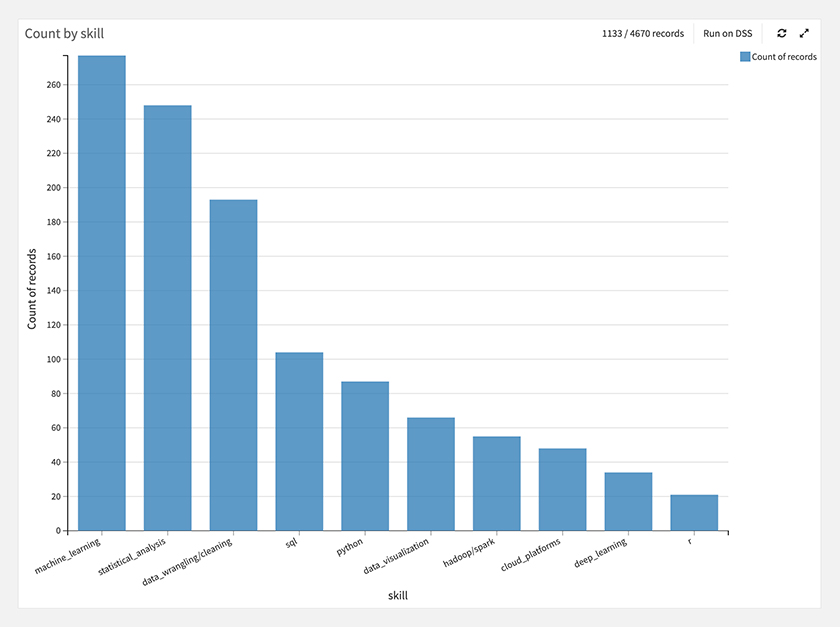
まず、各スキルでどれくらい求人の件数があるかを見てみます。
機械学習、統計学、データクリーニングが多く、Rや深層学習は少ない事が分かります。
スキルの件数
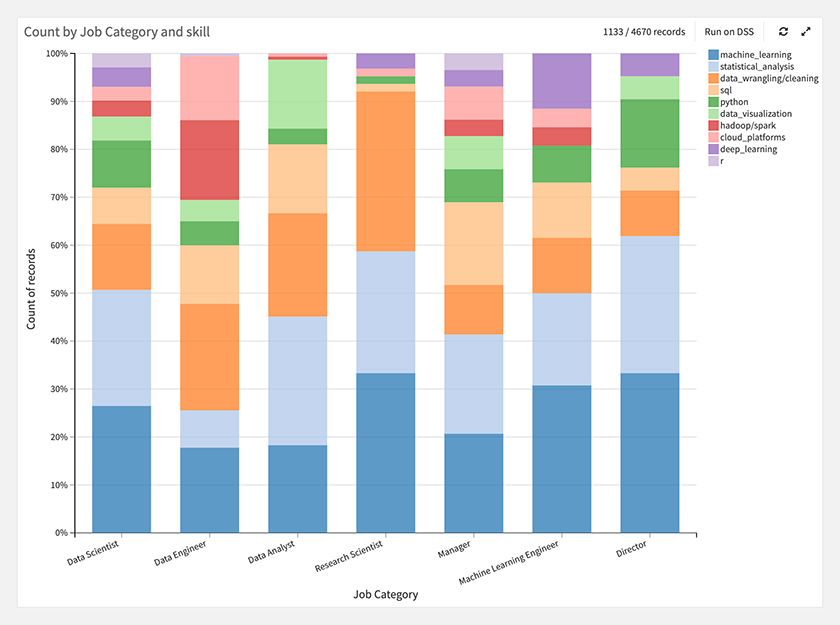
次に、職種カテゴリ別にどんなスキルが求められているのかを構成比で見てみます。
クラスタ間を比較すると、ざっくり以下のような特徴がありそうです。
・Data Engineer:Statistical Analysisが少なく、Hadoop/Spark、Cloud Platformsが多い
・Data Analyst:DataVisualizationが多い
・Research Scientist:Data wranging/cleaningが多く、SQL、Python、Cloud Platforms、Deep Learningが非常に少ない
・ML Engineer:Deep Learningが多い
・Director:Pythonが多い
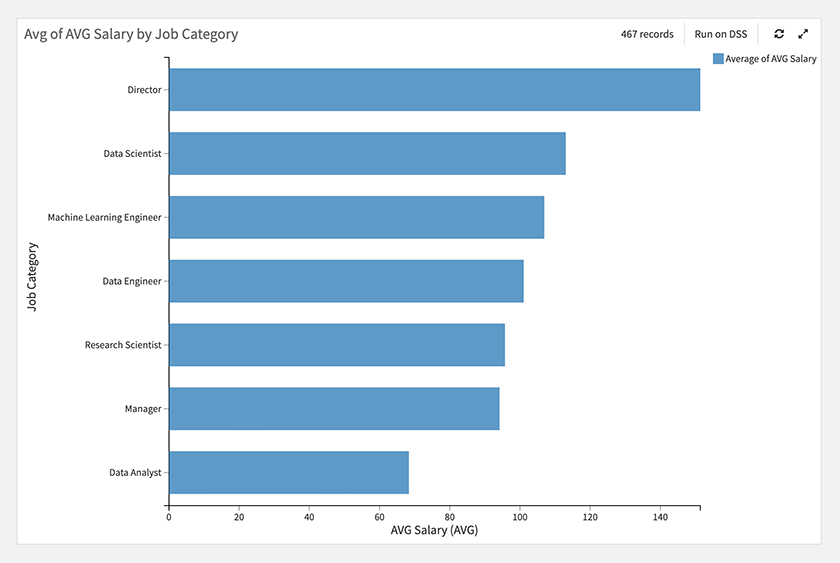
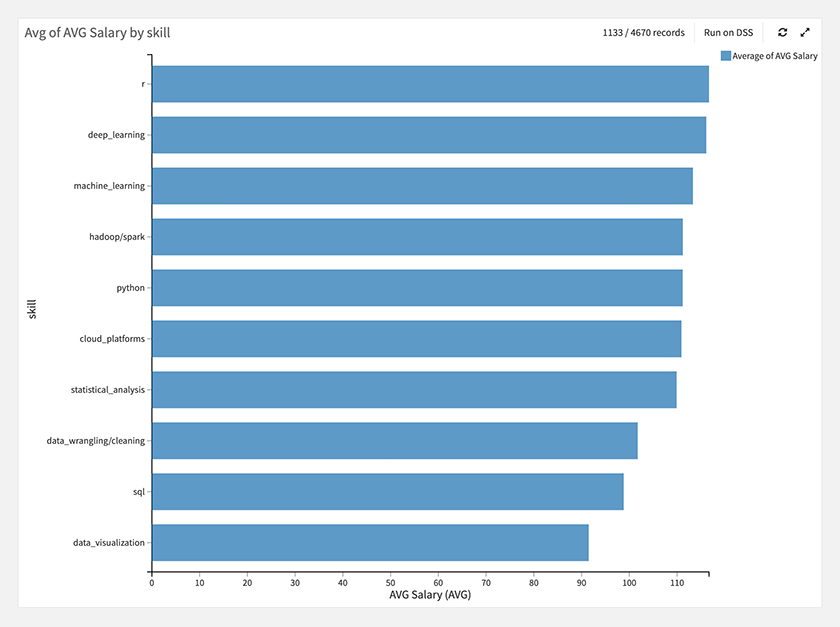
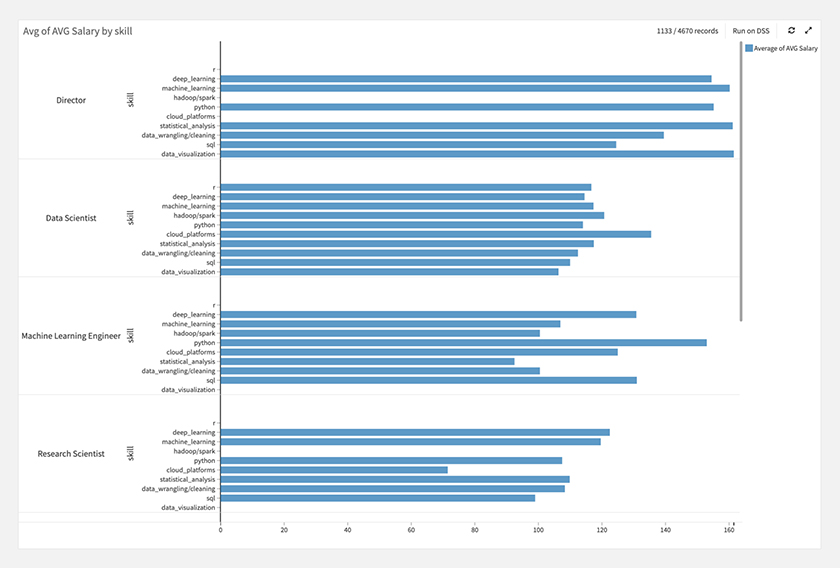
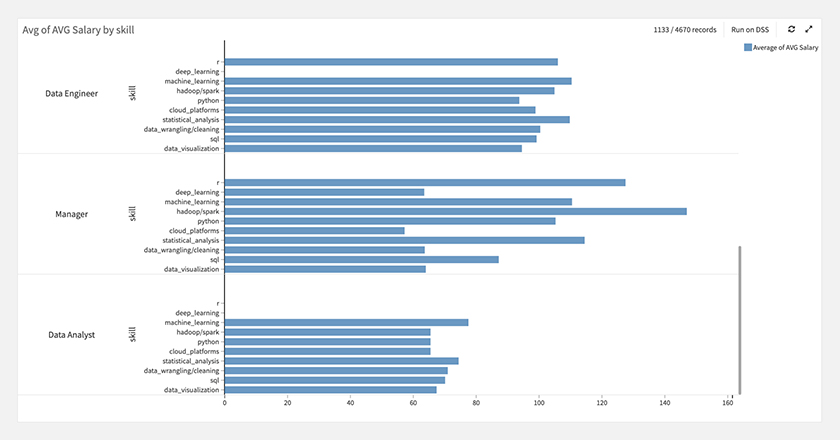
職種カテゴリとスキル毎に、給与を見てみると下図のような結果でした。
職種カテゴリでは、Directorが一番高く、Data Anaystが低い、スキルでは、RやDeep Learingの給与が高く、Data Visualizationが低くなっています。
クラスタリング
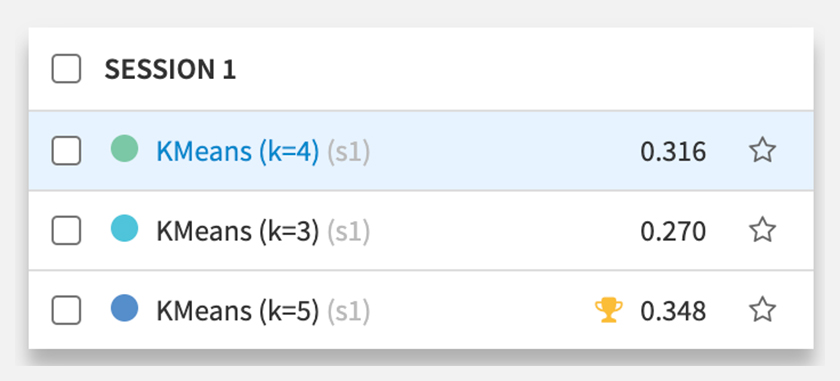
AutoML Clusteringでクラスタリングをしてみます。今回は、K-meansで次元削減(PCA)、クラスタ数3〜5で設定して実行したところ、下図のようにクラスタ数5のスコアが一番良い結果になりました。
クラスタリングの結果
続いて、クラスタの特徴をヒートマップで確認します。
クラスタの特徴
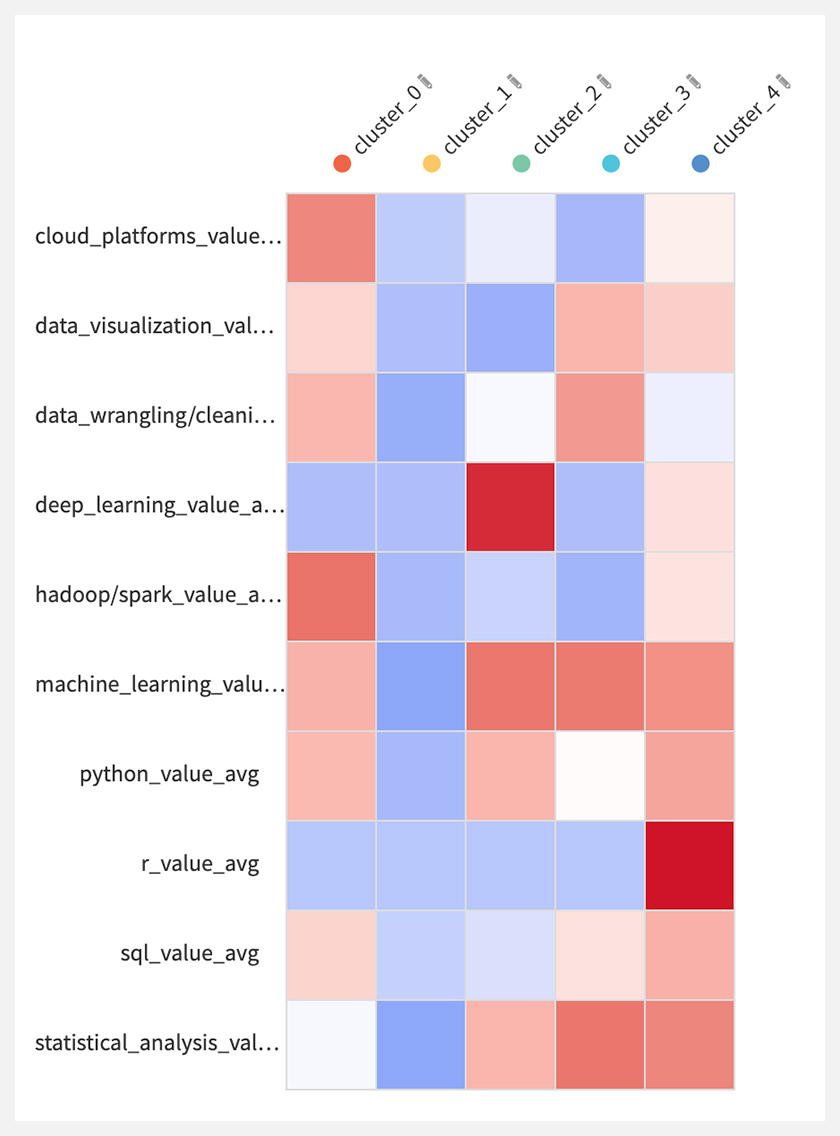
上図を見ると、どうやら以下のようなクラスタが作成されているようです。
ここでは、雑に「データ基盤」「スキルなし」「深層学習」「機械学習」「統計学」と呼ぶことにします。
・クラスタ0:Hadoop/Spark、Cloud Platforms
・クラスタ1:特徴なし
・クラスタ3:Machine learning、Statistical analysis、Data wrangling/cleaning
・クラスタ4:R、Statistical analysis、Machine learning
クラスタと職種カテゴリ・給与の関係
作成したクラスタ毎に職種カテゴリや給与の傾向を見ていきます。
構築したモデルをデプロイし、クラスタのラベルを追加したデータを作成します。
各クラスタの件数を見てみます。
下図のように、スキルなしと機械学習のクラスタが多く、深層学習と統計学のクラスタは少ないことが分かります。
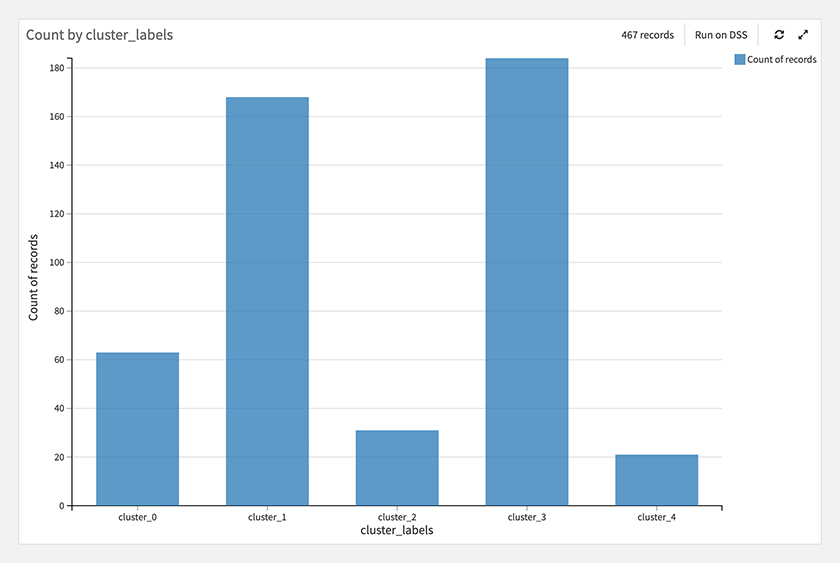
続いて、各スキルクラスタの給与を確認してみると、スキルなしのクラスタの給与が他と比べて低い傾向が見られました。
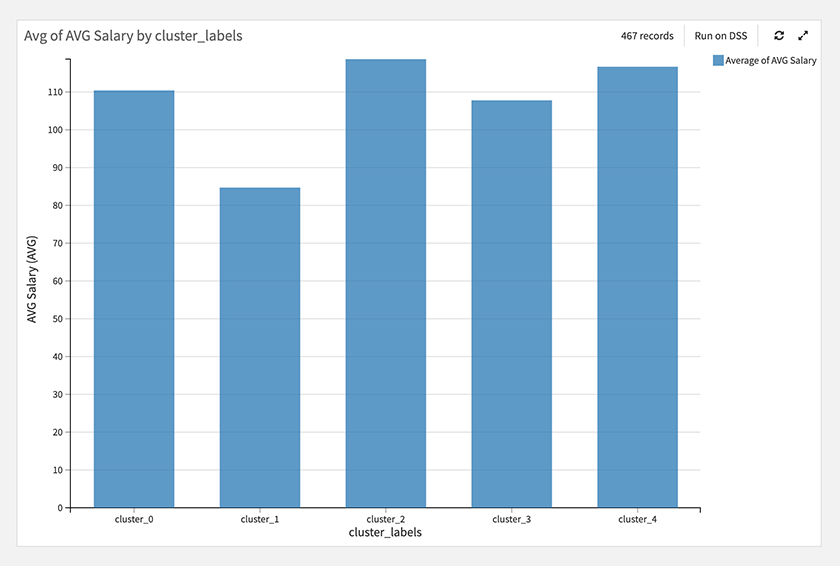
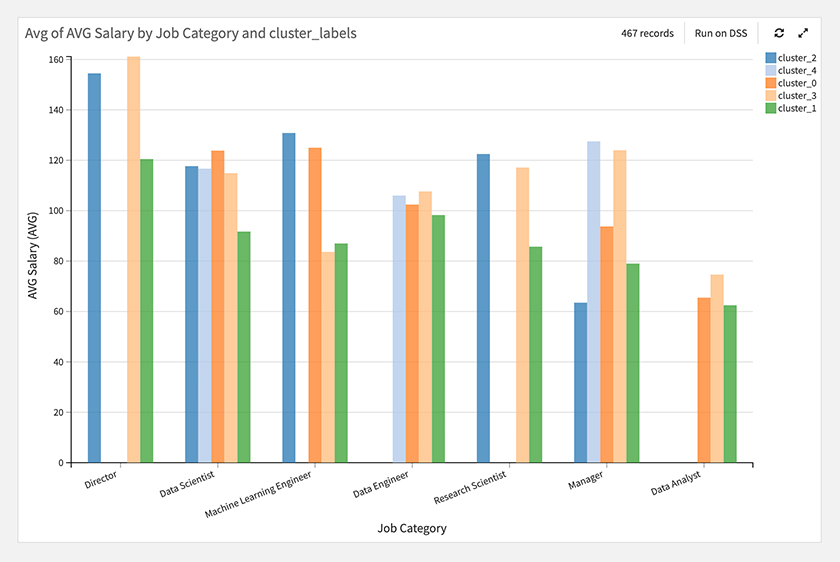
次に職種カテゴリ別スキルクラスタ別の給与を見てみます。ざっくりですが、以下のような傾向が見られます。
・Director:機械学習と深層学習のスキルがあると給与が高い
・Data Scientist:スキルによる給与の違いがあまりない(スキルなし除く)
・ML Enginneer:深層学習やデータ基盤のスキルがあると給与が高い
・Research Scientist:深層学習、機械学習のスキルがあると給与が高い
・Manager:統計学、機械学習のスキルがあると給与が高い
あと、深層学習のスキルは全体的に高めですが、Managerの場合は低くなっているのも興味深いですね!
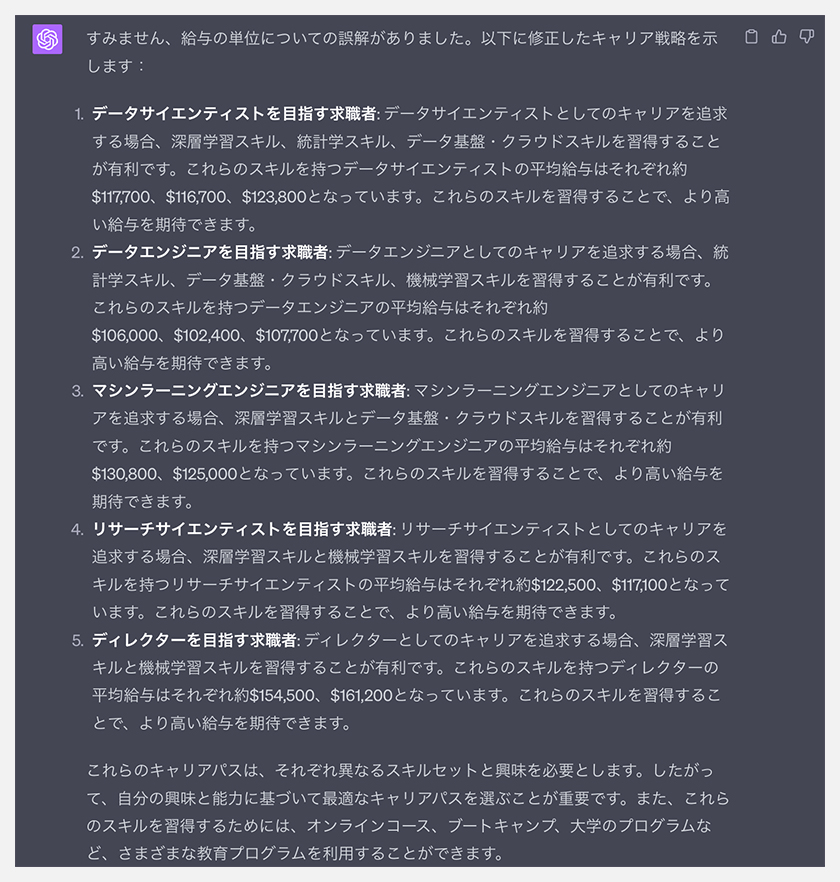
さて、ChatGPTにキャリア戦略を考えてもらいましょう。

単位を教えるのを忘れてました・・・笑

おわりに
本記事では、Dataikuで、職種カテゴリやスキルと給与の関係の可視化と、スキルを特徴量としたクラスタリングを実行しました。
今回データが少ないため、信頼性という面では怪しいところもありますが、DataikuやChatGPT活用の参考になるとうれしいです!
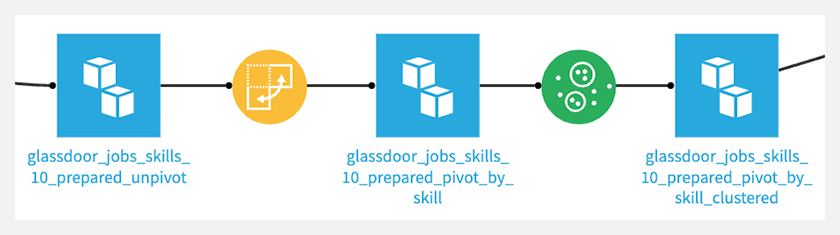
最後に、今回作成したフローを載せておきます。

APPENDIX
関連記事





本社 〒891-3604 鹿児島県熊毛郡中種子町野間5185-1
TEL : 0997-28-3393
支社 〒150-0022 東京都渋谷区恵比寿南1-20-6第21荒井ビル4F
TEL : 03-6890-2598